llm-d Inference Router Architecture
Overview
llm-d is an extensible architecture designed to route inference requests efficiently across model-serving pods. A central component of this architecture is the Inference Gateway, which builds on the Kubernetes-native Gateway API Inference Extension (GIE) to enable scalable, flexible, and pluggable routing of requests.
The design enables:
- Support for multiple base models and LoRA adapters within a shared cluster [Not supported in Phase1]
- Efficient routing based on KV cache locality, prefix, session affinity, load, and model metadata
- Disaggregated Prefill/Decode (P/D) execution
- Pluggable filters, scorers, and scrapers for extensible routing
Core Goals
- Route inference requests to optimal pods based on:
- Base model compatibility
- KV cache reuse
- Load balancing
- Support multi-model deployments on heterogeneous hardware
- Enable runtime extensibility with pluggable logic (filters, scorers, scrapers)
- Community-aligned implementation using GIE and Envoy + External Processing (EPP)
Architecture Design
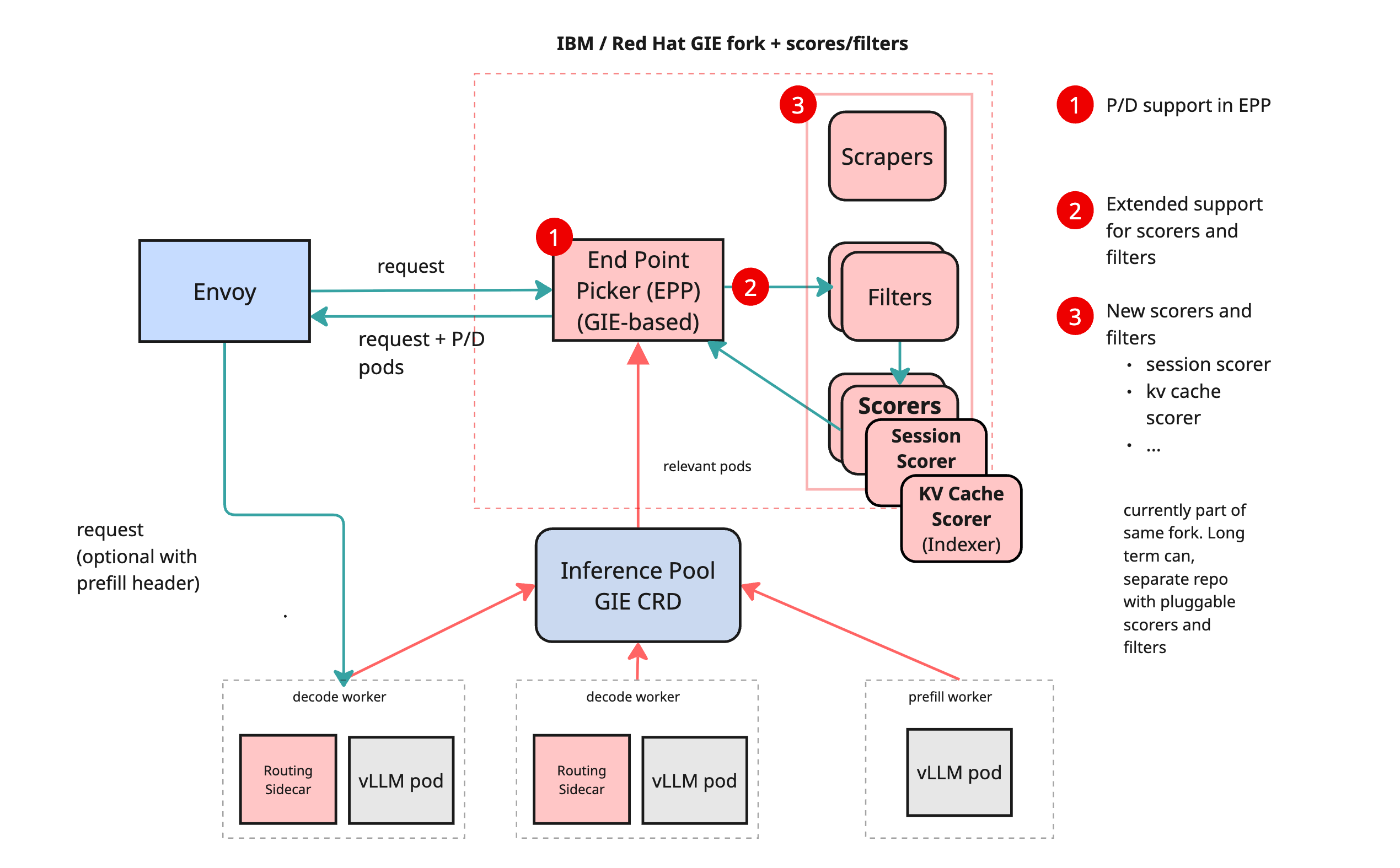
The inference scheduler is built on top of:
- Envoy as a programmable data plane
- EPP (External Processing Plugin) using GIE
Pluggability
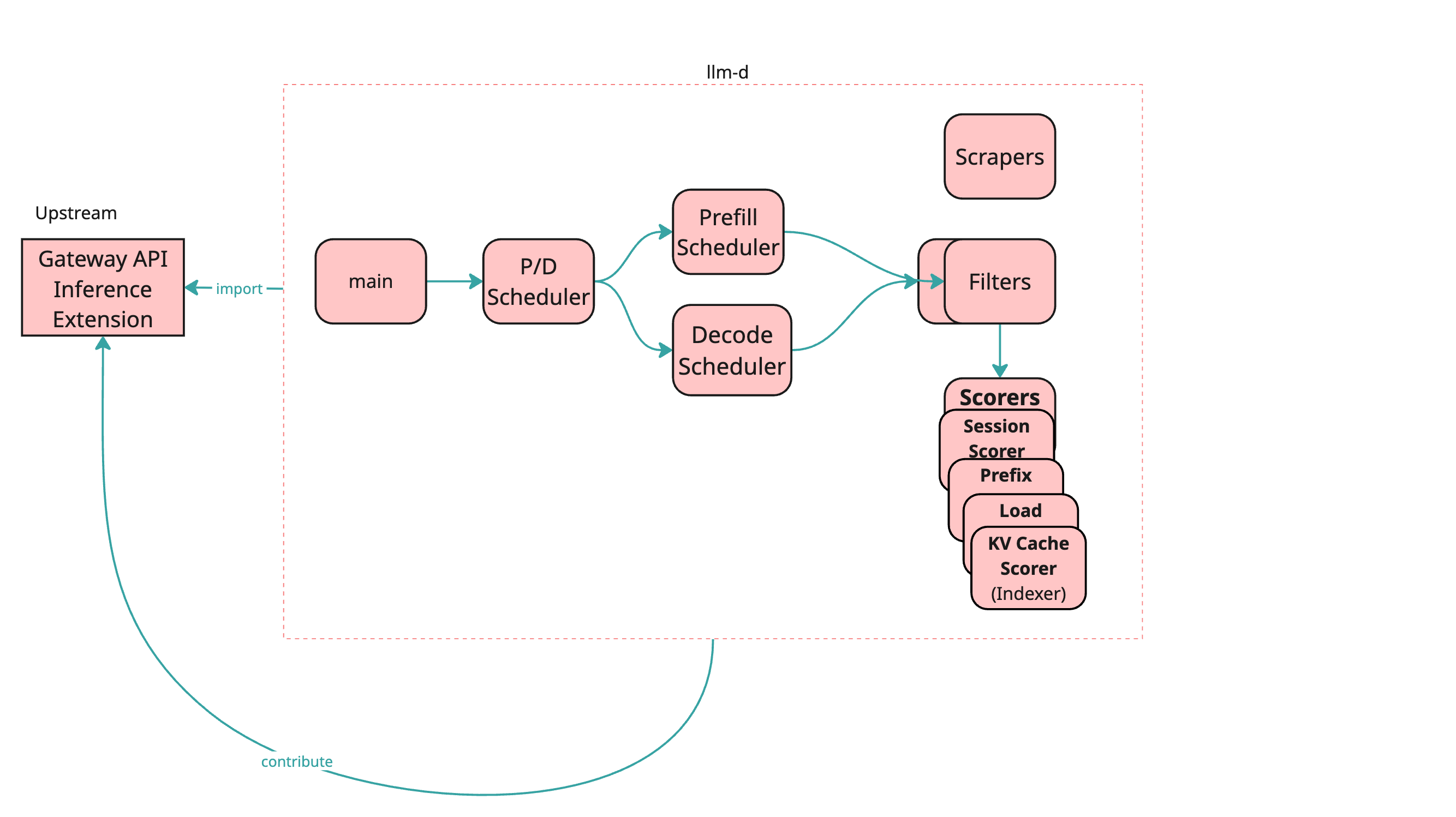
Routing decisions are governed by dynamic components:
- Filters: Exclude pods based on static or dynamic criteria
- Scorers: Assign scores to candidate pods
- Scrapers: Collect pod metadata and metrics for scorers
These components are maintained in the llm-d-inference-scheduler repository and can evolve independently.
Filters, Scorers, and Scrapers
Core Design Principles
- Pluggability: No core changes are needed to add new scorers or filters
- Isolation: Each component operates independently
Routing Flow
-
Filtering
- Pods in an
InferencePoolgo through a sequential chain of filters - Pods may be excluded based on criteria like model compatibility, resource usage, or custom logic
- Pods in an
-
Scoring
- Filtered pods are scored using a weighted set of scorers
- Scorers currently run sequentially (future: parallel execution)
- Scorers access a shared datastore populated by scrapers
-
Pod Selection
- The highest-scored pod is selected
- If multiple pods share the same score, one is selected at random
Lifecycle Hooks
Pre-callScoringPost-choiceAfter-response
Scorers & Configuration
| Scorer | Description | Env Vars |
|---|---|---|
| Session-aware | Prefers pods from same session | ENABLE_SESSION_AWARE_SCORER, SESSION_AWARE_SCORER_WEIGHT, PREFILL_ENABLE_SESSION_AWARE_SCORER, PREFILL_SESSION_AWARE_SCORER_WEIGHT |
| Prefix-aware | Matches prompt prefix | ENABLE_PREFIX_AWARE_SCORER, PREFIX_AWARE_SCORER_WEIGHT, PREFILL_ENABLE_PREFIX_AWARE_SCORER, PREFILL_PREFIX_AWARE_SCORER_WEIGHT |
| KVCache-aware | Optimizes for KV reuse | ENABLE_KVCACHE_AWARE_SCORER, KVCACHE_INDEXER_REDIS_ADDR, PREFILL_ENABLE_KVCACHE_AWARE_SCORER, PREFILL_KVCACHE_INDEXER_REDIS_ADDR, HF_TOKEN, KVCACHE_INDEXER_REDIS_ADDR |
| Load-aware | Avoids busy pods | ENABLE_LOAD_AWARE_SCORER, LOAD_AWARE_SCORER_WEIGHT, PREFILL_ENABLE_LOAD_AWARE_SCORER, PREFILL_LOAD_AWARE_SCORER_WEIGHT |
Prefill / Decode Configuration
In case Disaggregated Prefill is enabled, you should also define the following environment variables.
- Toggle P/D mode:
PD_ENABLED=true - Threshold:
PD_PROMPT_LEN_THRESHOLD=<value>
Prefill Scorers:
export PREFILL_ENABLE_SESSION_AWARE_SCORER=true
export PREFILL_SESSION_AWARE_SCORER_WEIGHT=1
export PREFILL_ENABLE_KVCACHE_AWARE_SCORER=true
export PREFILL_KVCACHE_AWARE_SCORER_WEIGHT=1
export PREFILL_ENABLE_LOAD_AWARE_SCORER=true
export PREFILL_LOAD_AWARE_SCORER_WEIGHT=1
export PREFILL_ENABLE_PREFIX_AWARE_SCORER=true
export PREFILL_PREFIX_AWARE_SCORER_WEIGHT=1
Metric Scraping
- Scrapers collect metrics (e.g., memory usage, active adapters)
- Data is injected into the shared datastore for scorers
- Scoring can rely on numerical metrics or metadata (model ID, adapter tags)
Disaggregated Prefill/Decode (P/D)
When enabled, the router:
- Selects one pod for Prefill (prompt processing)
- Selects another pod for Decode (token generation)
The vLLM sidecar handles orchestration between Prefill and Decode stages. It allows:
- Queuing
- Local memory management
- Experimental protocol compatibility
Note: The detailed P/D design is available in this document: Disaggregated Prefill/Decode in llm-d
InferencePool & InferenceModel Design
Current Assumptions
- Single
InferencePooland singleEPPdue to Envoy limitations - Model-based filtering can be handled within EPP
- Currently only one base model is supported