KV-Cache Wins You Can See: From Prefix Caching in vLLM to Distributed Scheduling with llm-d







The llm-d project provides a series of “well-lit paths” - tested, benchmarked solutions for deploying large language models in production. Our first path, Intelligent Inference Scheduling, established a baseline for AI-aware routing by balancing both cluster load and prefix-cache affinities. The default configuration for that path uses an approximate method for the latter, predicting cache locality based on request traffic.
This blog illuminates a more advanced and powerful path: precise prefix-cache aware scheduling.
We take a deep dive into the next generation of this feature, which moves beyond prediction and gives the scheduler direct introspection into distributed vLLM caches. This precision is key to maximizing cache hit rates and achieving a new level of performance and maximizing cost-efficiency in your distributed deployments.
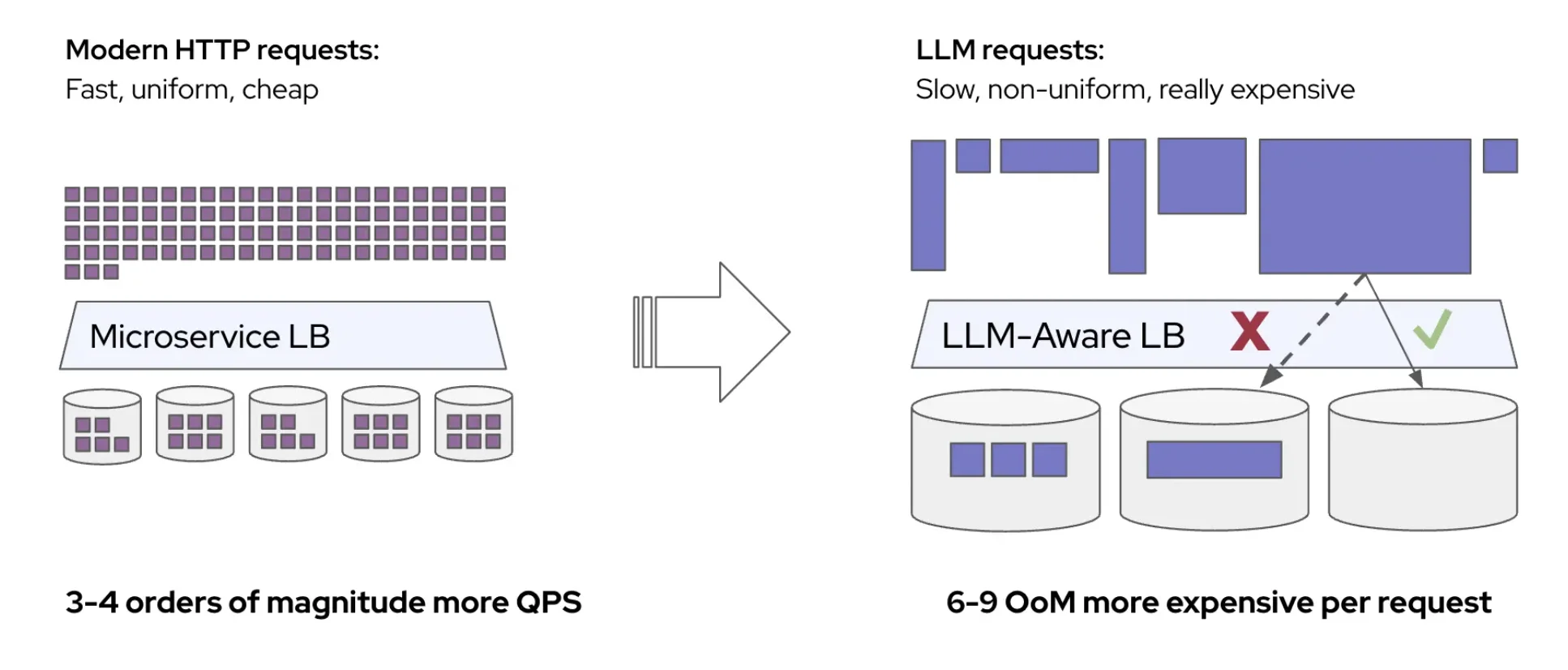
- KV-cache hit rates directly impact your bottom line: With 10x cost differences between cached and uncached tokens, cache efficiency isn't just a performance optimization — it's a fundamental cost and performance driver
- This isn't theoretical: Real production workloads like conversational AI and agentic workflows naturally create the prefix-heavy patterns where this approach excels
- vLLM's prefix caching breaks in distributed deployments: Standard load balancers scatter related requests across pods, destroying cache locality and forcing expensive re-computation
- Precise prefix-cache aware scheduling delivers order-of-magnitude gains: Our benchmarks show 57x faster response times and double the throughput on identical hardware