Native KV Cache Offloading to Any Filesystem with llm-d





llm-d is a distributed inference platform spanning multiple vLLM instances. KV cache hits are critical to achieving high inference throughput. Yet, in a distributed environment, cache hits do not occur across different nodes as the KV cache is local to each vLLM instance. In addition, this local cache is limited in size, further limiting KV data reuse. This blog presents a new way to offload KV cache to storage, tackling both aforementioned challenges – KV cache sharing and KV cache scale. llm-d's filesystem (FS) backend is a KV cache storage connector for vLLM that offloads KV blocks to shared storage based on vLLM's native Offloading Connector. While the llm-d FS backend can speed up serving of single requests (improve TTFT), its main goal is rather to preserve stable throughput and low latency at scale, as concurrency and context lengths grow. This is accomplished by significantly enlarging the cache space and enabling KV reuse across multiple replicas and nodes in llm-d.
While there are a number of existing solutions for KV cache offload to storage (e.g. LMCache or Dynamo KVBM), the new connector offers simplicity, can run with llm-d and vLLM as the only dependency, and exhibits improved performance over state-of-the-art shared storage connectors.
The Importance of KV-cache Reuse
In transformer-based inference, the prefill stage computes key and value (KV) tensors for the input tokens, which are then used when decoding output tokens. This stage is computationally intensive, especially for long input contexts. But once the KV tensors are available, they are kept in a KV cache and can be reused, avoiding the prefill computation entirely.
When the same prefix appears repeatedly - for example, shared system prompts, common documents, agentic loops, or multi-turn conversations - recomputing the KV tensors wastes significant compute. Reusing the KV cache allows the system to skip a large portion of the prefill work, reducing latency and improving overall throughput (a deeper dive on KV reuse use cases appears here).
Why Storage Offloading is Needed
vLLM already supports keeping KV-cache data in GPU (High Bandwidth Memory) HBM and, more recently, offloading KV to host memory. These approaches work well for a single server or small deployments, but they become limited at scale. GPU HBM is typically on the order of tens of gigabytes per GPU. CPU memory is usually larger but still on the same order of magnitude. For example, consider a high-end node hosting 8 GPUs with 2TB of DRAM. Divided by 8, the CPU DRAM per GPU is 250GB while the HBM is, say 80GB.
On the other hand, KV-cache takes up lots of space, especially with longer context lengths and higher concurrency from multiple users and requests. Even a medium-sized class model, such as Llama-3.1-70B, requires 305 GB of KV-cache for one million tokens. Storage scales nearly infinitely compared to memory solutions and offers a far superior $ per GB ratio.
In addition, shared storage is a simple method to share KV data across an entire cluster spanning multiple vLLM instances and physical nodes. New nodes added to a cluster can immediately benefit from existing KV-cache data without warming the cache from scratch. Shared persistent KV-cache also benefits post-peak scale-down since localized KV-cache data is not lost. Finally, KV-cache persistence matters, so cached data is not lost during restarts or rescheduling events.
What We Built: llm-d FS Backend
The llm-d FS backend is a storage backend that plugs into vLLM's Offloading Connector. It stores KV blocks as files on a shared filesystem and loads them back on demand. It uses the filesystem directory as the index of what KV values are in the storage, and as such is persistent and sharable across all nodes connected to the filesystem.
The following are some key properties of our solution:
- Filesystem agnostic: Relies on standard POSIX file operations, so it works with any standard filesystem.
- KV sharing across instances and nodes: Multiple vLLM servers can reuse cached prefixes by accessing the same shared path.
- Persistence across restarts or failures: KV data can survive pod restarts, rescheduling, and node failures (depending on storage durability).
- Enterprise storage integration: Can leverage mature storage systems with existing durability, monitoring, and access control.
In addition, the following performance-related design choices were made:
-
Fully asynchronous I/O: By using vLLM's Offloading Connector KV reads and writes can run without blocking the main path. Details about the vLLM offloading connector can be found here.
-
High throughput via parallelism: I/O operations are parallelized across worker threads to increase bandwidth and reduce tail latency.
-
Minimal interference with GPU computations: Default transfers use GPU DMA, reducing interference with compute kernels.
How to Use it
Using the FS offloading connector is simple, requires a pip install, and a directory path to the storage being used. Other optional tunable parameters are the storage block size (in tokens) and the number of worker threads.
Detailed instructions can be found in the llm-d well-lit path guide.
Note that while the results presented in this blog were of tests run with IBM Storage Scale, the connector was also tested with other storage options including local storage (NVMe drive with a filesystem mounted on it) and CephFS. In general it will work seamlessly with any storage supporting a filesystem API or that has a filesystem mounted on it.
Results and Benchmarks
Single request speed-up
Depending on storage speed, loading KV data from storage can dramatically reduce TTFT compared to prefilling. We start by examining the benefit that offloading of KV data to storage can have on the speed of a single request, while emphasizing that the main benefit of offloading KV to storage (supporting high throughput at scale) will be shown later on.
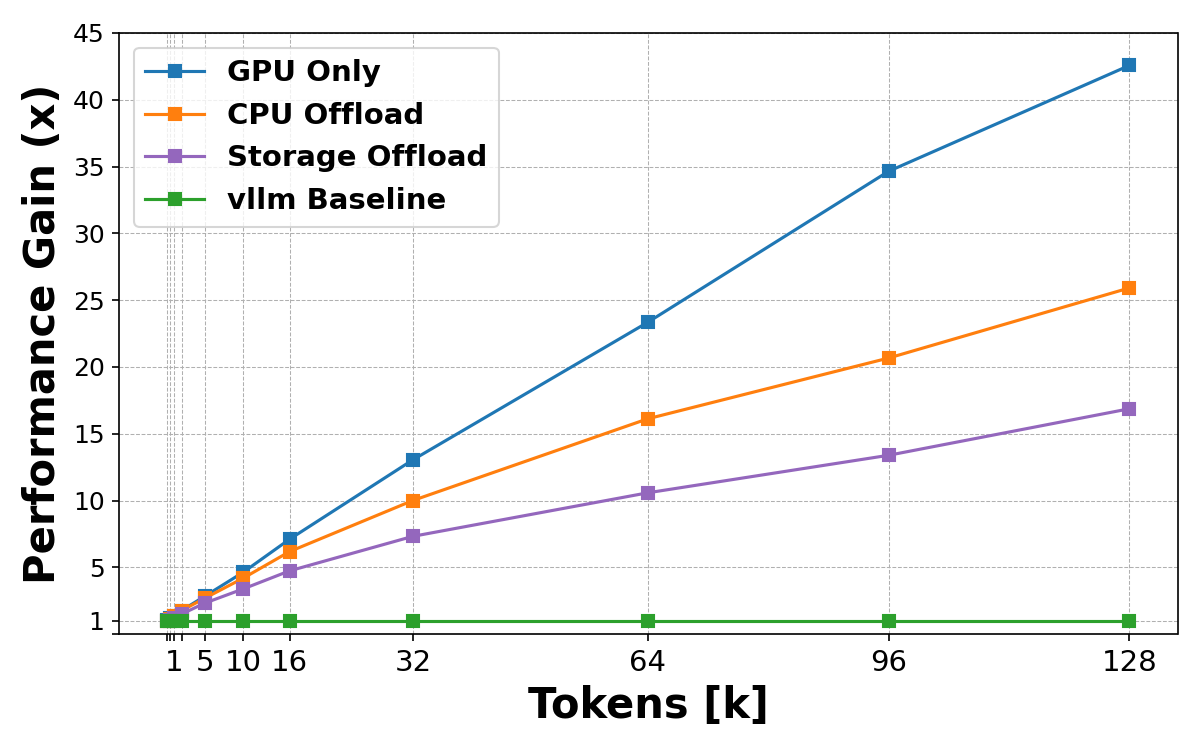
Figure 1: Single-request KV-cache load across tiers
In Figure 1, we measure the TTFT for a single request as the number of tokens increases using various offloading mediums. This shows the evaluation for a Llama-3.1-70B model on a system with 4x NVIDIA H100 GPUs and an IBM Storage Scale. We compare KV loading from GPU memory, CPU memory, and shared storage and measure the speedup achieved vs. Prefill (a KV cache miss).
As the number of tokens increases, KV loading becomes increasingly efficient compared to recomputing the same tokens during prefill, achieving a speedup of up to 16.8X on long prompts. However, for single-request workloads, GPU and CPU caching remain the faster options. This is because storage, for the most part, is slower than DRAM (with some exceptions). Moreover, transferring data between storage and GPU HBM usually involves an additional hop via CPU DRAM, which adds to its overhead. This is a fundamental reality that reinforces why CPU offloading and smart routing based on prefix cache hits remain valuable optimizations in the llm-d system, even with shared storage available. Storage is not intended to replace these mechanisms, but to complement them. Its main value lies in providing far greater scalability, significantly lower cost per gigabyte, and persistent KV storage.
Scalability test
In order to exemplify the benefit of storage for scalability, we start by examining a somewhat artificial workload that consists of multiple users, where each user has their own distinct system prompt (we will consider a more realistic workload in the following section). We ask how many concurrent users a single vLLM node can support without a significant drop in throughput due to cache misses.
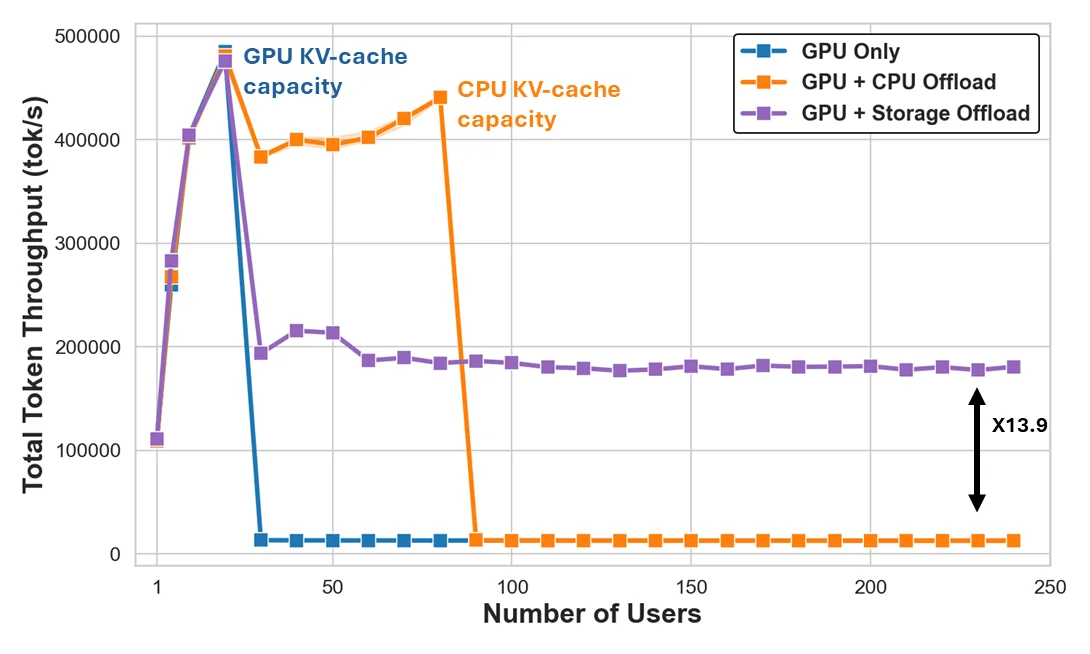
Figure 2: Multiple-request KV-cache load across tiers
In Figure 2, we evaluate KV-cache loading under varying concurrency levels by issuing 16K token requests from a growing number of users. In this test, all prompts have previously appeared, and the decode is of a single token. We chose this extreme workload just to emphasize the point, and we will show a more realistic workload next. Again, we used a single node running Llama-3.1-70B on a system with 4x NVIDIA H100 GPUs and an IBM Storage Scale filesystem.
We see that only a small number of user prompts can fit in GPU memory. With such a small number of users, performance is extremely fast, but once we grow beyond this, performance drops significantly as essentially almost all requests undergo prefill. With CPU offloading, this drop-off is postponed, and the system can handle a higher (yet limited) number of users with a very small drop-off for these. On the other hand, storage-backed KV caching shines once we scale up. While the speed offered by storage does not match that of the GPU or CPU, it allows the system to sustain throughput as the working set increases nearly infinitely.
This experiment highlights the key benefit of storage offloading: it prevents performance collapse when workloads outgrow GPU or CPU cache capacity. The gains come from higher cache hit ratios at scale and from shared access across replicas. Its value lies in maintaining throughput and latency stability as workloads exceed the capacity of GPU or CPU memory, supporting efficient scaling of the system. This also highlights that storage performance is key to achieving high throughput on KV cache hits.
Scalability in realistic workloads
Finally, we evaluate a more realistic workload that mixes KV loading, prefill, and decode operations. We use the llm-d benchmarking framework to run inference-perf with a shared-prefix synthetic workload. Each query consists of a previously seen user-specific system prompt of 2000 tokens and a question made of 256 tokens. 256 tokens are decoded in response. The queries are issued at a rate of 40 QPS from a pool of users of variable size. The more users in the system, the greater the working set size is and hence the more we expect storage to shine. This setup helps us study how the different caching options behave with a growing number of users. This setup runs llm-d with two decode nodes executing a Llama-3.1-8B model on a system with 2x NVIDIA H100 GPUs and a cloud-based storage offering approximately 10GB/s I/O throughput.
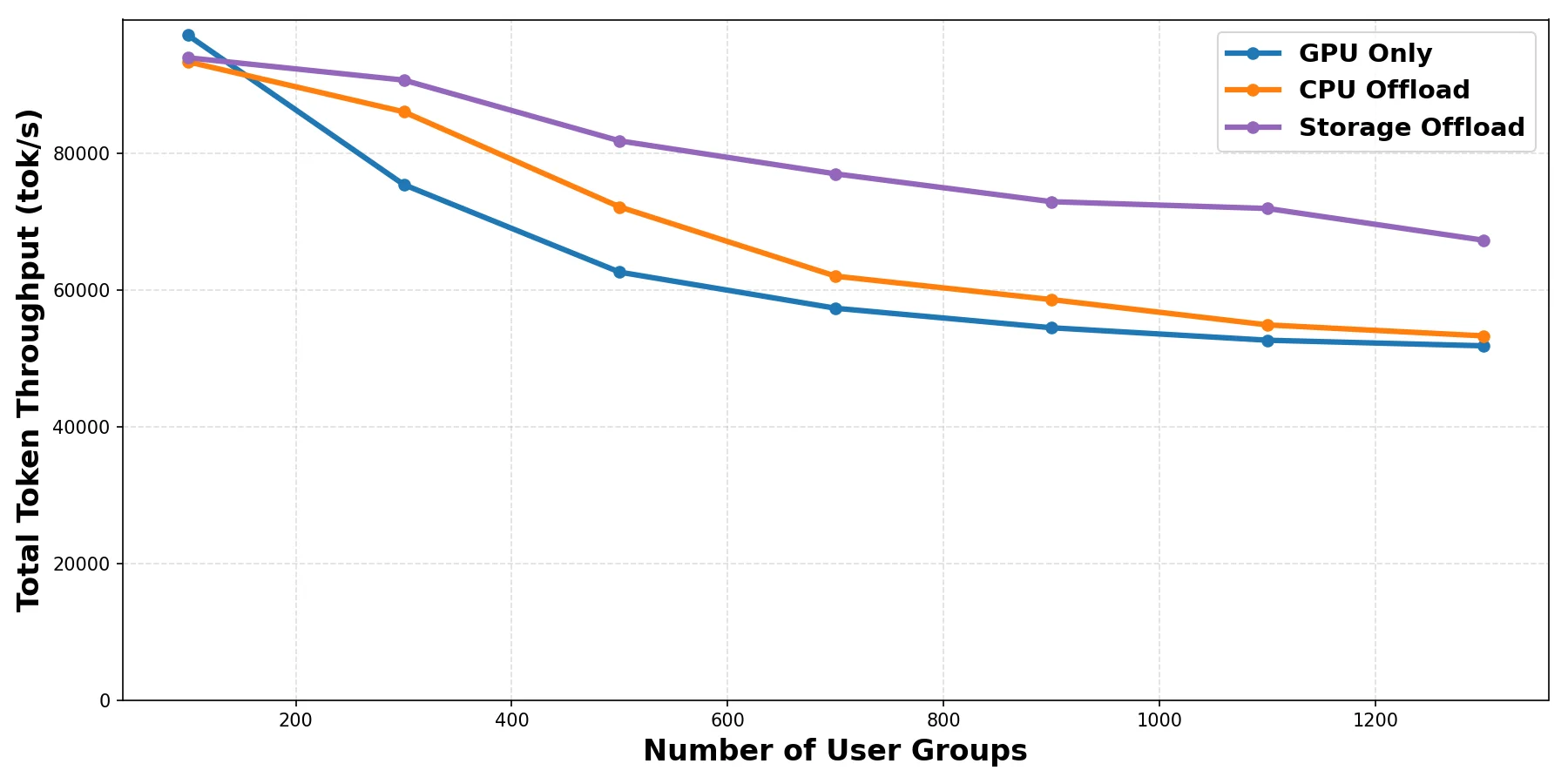
Figure 3: Multiple requests with mixed workload (load + prefill + decode)
The results, in Figure 3, show similar behavior to the previous test. By extending KV-cache capacity using shared storage, llm-d can reuse KV data more effectively across requests and replicas, maintaining an improved overall throughput and TTFT as the system scales. An additional important observation is that even though the storage in this test was not top-end, the asynchronous use of storage frees up precious GPU cycles for prefill and decode operations and hence achieves higher throughput.
Summary and Next Steps
Storage offloading is an important and essential capability for scalable AI inference platforms such as llm-d. It increases effective KV-cache capacity, enables cross-replica reuse, and makes llm-d clusters more elastic by allowing them to scale efficiently with growing request volume and user concurrency. The FS backend keeps the integration native to vLLM and llm-d, using an asynchronous design and high-throughput transfers built around parallelism.
The initial FS backend is the first llm-d native solution for storage KV offloading. As next steps, we are working on new features, including tiered storage offload (as a second tier to CPU DRAM), integration with NIXL backends, offloading to object storage, support for GPU Direct Storage (GDS), and more.
Acknowledgement
For performance testing, we used IBM Storage Scale, an enterprise-level storage system offering high performance, scalability, and reliability.